Infrastrukturen der Dis-Diskonnektivität
Am 9. April 2018 fällt gegen 20 Uhr der gemessen am Datendurchsatz größte Internetknoten der Welt für mehrere Stunden aus, der DE-CIX (Deutsche Commercial Internet Exchange) in Frankfurt am Main mit einem Volumen von bis zu 6 Terabit pro Sekunde.[1] Die Auswirkungen des vierstündigen Ausfalls auf den Betrieb des Internets sind minimal. Stellt man sich als Kontrast die Verkettung globaler Auswirkungen vor, wenn der größte Flughafen ausfallen würde, wird eine Spezifik der Infrastrukturen des Internets besonders deutlich: Sie sind durch Verfahren der Redundanz und Resilienz in der Lage, Schäden, Ausfälle und Unfälle innerhalb kürzester Zeit zu absorbieren, sodass selbst der durchsatzstärkste Knotenpunkt vom Netz gehen kann, ohne dass der Betrieb beeinträchtigt würde.
Dieser technische Zwischenfall führt zu keiner disconnection des Internets. Ganz im Gegenteil zeigt sich dessen infrastrukturelle Kapazität, trotz temporärer Ausfälle ununterbrochenen Betrieb aufrechtzuerhalten. Doch die Frage, ob man das Internet ausschalten kann, ist keineswegs so simpel, wie es auf den ersten Blick scheinen mag. Denn wenn man das Internet durch eine Beschädigung seiner Infrastrukturen nicht ausschalten kann (auch wenn man damit großen Schaden anrichten kann[2]), dann hat dies Konsequenzen für das Potential von Praktiken der des withdrawal und der disconnection – ein Begriff, der mit der inhärenten Negation der Verbundenheit kein Äquivalent im Deutschen hat. So wie diese Praktiken in den populären Diskursen vertreten werden, beruhen sie auf einer Differenz zwischen einer aktiven Agency des sich zurückziehenden Users und einer passiven Gegebenheit technischer Infrastrukturen. Diese Zuschreibung wird fraglich, wenn man die Kapazitäten dieser Infrastrukturen zu Resilienz und Redundanz in den Blick nimmt und damit ihre Un-Abschaltbarkeit (dis-disconnectivity). Mit dieser Verabschiedung der zugrundeliegenden Differenz verändert sich insbesondere das ethische Potential der Diskurse der disconnection: Wenn disconnection oder withdrawal zwar aktive menschliche Praktiken sind, die aber keinen Umgang mit einer allein instrumentell verstandenen Infrastruktur bedeuten, sondern diese selbst in die Möglichkeitsbedingungen von disconnection interveniert, dann verlieren die Praktiken der disconnection und des withdrawal ihr emanzipatorisches Potential. Dieses stützt sich – zumindest in den populären Positionen – auf einen maschinenstürmerischen Anspruch, der nur solange eingelöst werden kann, wie es möglich ist, die Maschinen zu stürmen. Auf individueller Ebene mag withdrawal möglich sein, doch als politische Praxis müsste sie die Unabschaltbarkeit des Internets berücksichtigen. Gibt es keinen technischen Modus der disconnection, dann bleiben die individuellen Praktiken der disconnection blind für die Infrastrukturen, die jene Konnektivität bedingen, von der man sich verabschieden möchte. Entsprechend gilt es nun, jene Infrastrukturen des Internets zu analysieren, die seinen ununterbrochenen Betrieb aufrechterhalten.
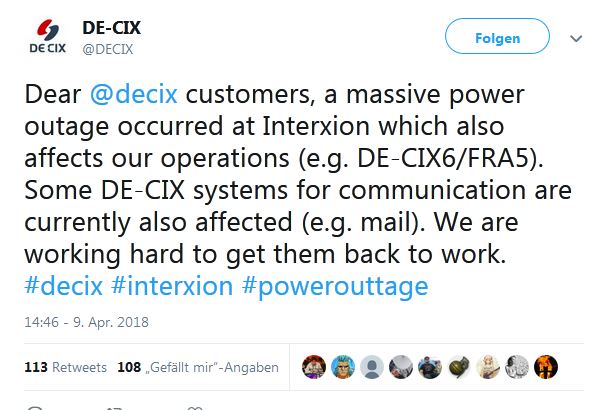
Gegründet 1995, entsteht der DE-CIX als ein gemeinsames Projekt dreier früher deutscher Internet Service Provider (ISPs) und ist heute ein international agierendes Unternehmen, das dreizehn Internet Exchange Points (IXP) weltweit unterhält.[3] DE-CIX betreibt jedoch, wie viele andere IXPs auch, keine eigenen Rechen- oder Datenzentren, sondern nimmt für die distribuierte Switch-Infrastruktur die Dienste anderer Unternehmen in Anspruch. Eine Verkettung von Ausfällen beim Rechenzentrums-Dienstleister Interxion, der Teile der über 21 Standorte in Frankfurt verteilten Routing-Server von DE-CIX betreut, sorgt am 9. April 2018 dafür, dass der Switch DE-CIX 6/Interxion FRA 5 in Frankfurt-Fechenheim längere Zeit nicht verfügbar ist. Dieser bedeutende Knoten dient vor allem dem Peering, d.h. dem Verschalten von Netzwerken zum Datenaustausch – also dem, was den technischen Kern des Internetwork Internet ausmacht: das Verbinden von isolierten Netzwerken untereinander. Zu den angeschlossenen Kunden von Interxion gehören neben DE-CIX vor allem Geschäftskunden, jedoch sind auch all jene Internet Service Provider betroffen, welche die Dienste von DE-CIX nutzen – im Fall dieses Teilausfalls rund 40 % der 850 DE-CIX-Kunden, zu denen auch große Unternehmen mit Firmennetzwerken zählen.[4] Der DE-CIX wird nicht direkt von Endnutzern angesteuert; vielmehr kaufen deren Provider bei DE-CIX Bandbreite und leiten dann ihren Traffic aus den eigenen Netzen über diesen Knoten in die Netze anderer Provider und Dienste (peering). Deshalb sind auch nicht alle Internet-User gleichermaßen und direkt vom Ausfall betroffen, sondern vornehmlich Kunden von Providern, in deren Auftrag DE-CIX genau dieses Rechenzentrum in Anspruch nimmt.
Der DE-CIX ist, so wird bereits deutlich, weniger ein zentraler Ort, an dem sich, gleichsam als Zentrum innerhalb des Netzwerks, der Knoten befindet, sondern ein über mehrere Standorte und Anbieter verteiltes Netz aus Netzwerkknoten. Diese Redundanz wird zum entscheidenden Faktor. Es fällt strenggenommen nicht ‚der DE-CIX‘ aus, sondern ein Knoten des Knotens. Ein IXP stellt innerhalb des Netzwerks einen sogenannten single point of failure dar, dessen Totalausfall ernstzunehmende Folgen für das gesamte Netz haben könnte.[5] Deshalb ist ein IXP kein Punkt, sondern selbst ein Netz. IXPs sind über mehrere Standorte, manchmal sogar mehrere Länder verteilt. Die anderen Standorte von DE-CIX sind aufgrund dieser räumlichen Verteilung während des Ausfalls weiterhin erreichbar. Da vermutlich jeder mitteleuropäische Internet-User die Dienste von DE-CIX täglich zur Übertragung von Tausenden von Datenpaketen nutzt, fällt der Ausfall jedoch sofort ins Gewicht.
Neben dem direkten Ausfall durch Unerreichbarkeit der von Interxion geleisteten Dienste stehen die indirekten Auswirkungen beeinträchtigter Konnektivität. Da nach dem Ausfall der nunmehr fehlgeleitete Traffic über benachbarte Knoten umgeleitet werden muss, wofür wiederum eine Anpassung der sogenannten Routing-Tables nötig ist, die jedem Router zur Ansteuerung des nächsten Knotens zur Verfügung stehen, kommt es für kurze Zeit zu großflächigen Verstopfungen und nicht erreichbaren Websites, abbrechenden Streams und unterbrochenen Downloads. Nach wenigen Minuten stellt sich jedoch bereits weitestgehend Normalbetrieb ein. Das mitteleuropäische Internet verkraftet also den Ausfall des größten Knotens und reguliert sich selbst durch automatische Umverteilung auf alternative Knoten.
Potentiale der Disconnection
Im Folgenden möchte ich diesen Zwischenfall zum Anlass nehmen, um nach dem Ausfall-Potential des Internets zu fragen, also nach den Strategien und Technologien, die einen Totalausfall kritischer Infrastrukturen verhindern sollen.[6] Diese Frage geht über die technischen Kapazitäten hinaus. Sie gewinnt ihre Brisanz vor dem Hintergrund einer anderen, selbstbestimmten Unterbrechung: der Trennung, der disconnection oder des withdrawal. Mit dem Anspruch auf ein Recht auf disconnection, wie es von Autoren wie Jaron Lanier oder Byung-Chul Han vertreten wird, sind unterschiedliche Weisen des Ausstiegs gemeint: von der Nicht-Nutzung bestimmter Dienste (vornehmlich Social Media) bis hin zu kompletter digitaler Abstinenz. „Quitting is the only way, for now, to learn what can replace our grand mistake.“[7] Solche Positionen propagieren den individuellen Abschied von digitalen Medien und vom Internet, aus unterschiedlichen Gründen, bleiben aber, wie Pepita Hesselberth ausgeführt hat, an widersprüchliche Annahmen darüber gebunden, was es heißt, aus einem Netzwerk auszusteigen.[8] Doch ist das Internet eine Infrastruktur, die man abschaffen, zerstören oder auflösen kann? Kann man das Internet hintergehen, und zwar nicht auf individueller Ebene, sondern auf soziotechnischer Ebene als kollektives Phänomen? Kann man es abschalten?
Als Praktik meint disconnection einen freiwilligen Zustand der Unverbundenheit, in dem User nicht mehr Teil des Netzes ist. Disconnection heißt nicht nur, keinen Anschluss mehr zu haben, sondern das Netz zu verlassen und – im Sinne des withdrawal – ein Außen im Innen zu erzeugen. Und das wiederum bedeutet, nicht Teil der Topographie und nicht adressierbar zu sein. Wer nicht Teil des Netzes ist, wer also keine Adresse hat, existiert in der Ontologie des Netzwerks nicht. Was nicht adressierbar ist, das ist nicht nur nicht Teil des Netzes, sondern hat für dieses keinen Status der Existenz.
Die Intuition dieses Essays lautet, dass individuelle und technische disconnection nicht voneinander getrennt werden sollten: Individueller Entzug, ob als Abmelden von Facebook oder als Ausschalten des Routers führt zwar zu dem, was Urs Stäheli Entnetzung genannt hat, aber nicht zur disconnection von digitalen Infrastrukturen.[9] Was nicht ausfallen kann, von dem kann man sich nicht verabschieden und das kann man auch nicht ausschalten. Wenn man das Internet nicht ausschalten kann, dann bleibt disconnection ex negativo an den Betrieb gebunden. Als vermeintlich emanzipatorischer Akt ignoriert der Ausstieg die Tatsache, dass man das Internet als Netzwerk nicht abschalten kann, sondern dass vielmehr ausdifferenzierte Verfahren existieren, um eben dies zu verhindern. Damit stellt sich die Frage nach dem Dispositiv, das Konnektivität, reibungsfreien Betrieb und ständige Verfügbarkeit als infrastrukturelle Bedingung sicherstellt.
Strategien der Redundanz und der Resilienz machen das Internet als komplexes, dynamisches System mit einer extremen Dichte an Komponenten zu einem Netzwerk, das technisch betrachtet nicht als Netzwerk, das Netze miteinander verschaltet, ausfallen kann. Sie können als Sicherheitstechnologien für Kritische Infrastrukturen verstanden werden, die man, Andreas Folkers Studie zur Biopolitik vitaler Systeme folgend, als Bestandteil eines Sicherheitsdispositivs der Resilienz deuten kann.[10] Die technische Resilienz des Internets, die durch Redundanz für seinen ununterbrochenen Betrieb sorgt, kann vor diesem Hintergrund als biopolitische Maßnahme (im Sinne Michel Foucaults) begriffen werden, mit der komplexe Infrastruktursysteme Kapazitäten der Adaption an unsichere Umgebungen herausbilden. Die gegen den Ausfall gerichteten Strategien, von denen hier nur ein kleiner Ausschnitt betrachtet werden kann, machen deutlich, dass man es sich mit der simplen Variante des Ausstiegs im Sinne Laniers oder Hans zu einfach macht. Vielmehr ist die Verhinderung des Ausfalls Teil eines Sicherheitsdispositivs, das auch die Optionen der disconnection oder des withdrawal bestimmt. Um über disconnection nachzudenken, sollte also zuerst in groben Zügen dieses Sicherheitsdispositiv herausgearbeitet werden, damit die Bedingungen von disconnection sichtbar werden. Erst dann wäre anhand der politischen wie technischen Konsequenzen eine theoretische Grundlage geschaffen, auf der über individuelle disconnection als politische wie technische Praxis oder über ihre Unmöglichkeit nachgedacht werden kann, die nicht auf einer Gegenüberstellung aktiven Handelns und passiver Technologie beruht. Disconnection ist nie ein souveräner Akt der Trennung, sondern stets bedingt von den technischen Infrastrukturen und Dispositiven, die Trennung auf spezifische Weise ermöglichen oder verhindern.
Der Ausfall
Ein von der Frankfurter Allgemeinen Zeitung zitiertes Schreiben von Interxion an die Kunden klärt kurz nach dem Zwischenfall über die Verkettung unglücklicher Umstände am 9. April 2018 auf: Zunächst fällt ein Transformator, der den Strom des lokalen Versorgers Mainova in das Netz des Rechenzentrums einspeist, durch Überhitzung aus. Die drei Dieselgeneratoren, die für solche Situationen wie in allen größeren Rechen- und Datenzentren bereitstehen und durch ihre Anzahl Redundanz ermöglichen sollen, laufen zwar wie im Notfallplan festgelegt an, doch durch einen weiteren Ausfall versiegt der Zufluss von Kraftstoff zu den Generatoren, obwohl ausreichend Diesel zur Verfügung steht. Das Sicherungssystem habe irrtümlicherweise ein Leck angezeigt und aufgrund einer leeren Stickstoff-Flasche den Kraftstoffzufluss gekappt.[11] Der Schaden ist zu dieser Zeit, als die Anlage mit Notstrom aus den zur kurzzeitigen Überbrückung gedachten Batterien weiterarbeitet, noch nicht behoben. Es steht kein Strom mehr zur Verfügung und der Knoten fällt von 19:43 bis 23:28 aus. Am frühen Morgen folgt ein weiterer Ausfall von etwa zwei Stunden. Zum Zeitpunkt dieses zweiten Ausfalls hat DE-CIX den Traffic bereits manuell umgeleitet.[12] Erst gegen vier Uhr morgens am 10. April sind alle Services wieder uneingeschränkt nutzbar. [13]
Die Folgen bleiben zwar für private Internetuser temporär – einige Internetseiten sind zeitweise nicht oder nur nach mehrmaligen Versuchen und das heißt Umleitungen erreichbar –, doch für die Geschäftskunden von DE-CIX weitaus einschneidender, weil ihre Dienste nicht funktionieren. Der Internetservice RIPE Atlas, eine offene Plattform mit unterschiedlichen Tools zur Messung aktueller Konnektivität, stellt nur wenige Tage nach dem Ausfall unter dem Titel „Does the Internet Route around Damage?“ ein Analyseprotokoll des über DE-CIX laufenden Traffics zur Verfügung. Anhand der traceroutes – ein Befehl, der die von einem Datenpaket durchlaufenen Knoten anzeigt –, wird einerseits die Größe des Ausfalls, andererseits aber auch die Geschwindigkeit der Wiederherstellung des Normalbetriebs deutlich – abzüglich von etwa zehn Prozent der Verbindungen, die auch einen Tag später nicht wieder über DE-CIX laufen. Jährlich treten etwa zehn bis fünfzehn ähnliche Ausfälle auf, die meist jedoch wesentlich schneller behoben sind und kleinere Knoten betreffen.[14] Ein Beispiel dafür ist der Ausfall des Amsterdam Exchange Point am 13. Mai 2015 für sieben Minuten. Aufgrund seiner Größe und Dauer ist der Ausfall des Frankfurter Knotens daher ein exemplarischer Fall, weil er die Reaktionen des Netzwerks im Krisenfall vorführt.
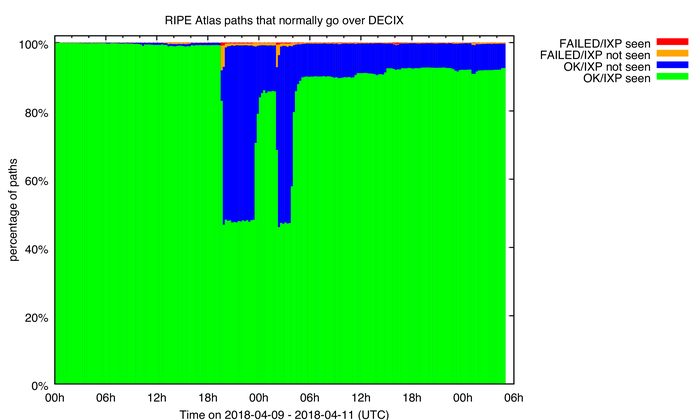
Emile Aben, Does The Internet Route Around Damage in 2018?, 11. April 2018.
Die von RIPE vorgestellte Analyse ist zugleich ein Zeugnis für das Nicht-Wissen über die selbstorganisierenden Prozesse des Internets als dynamischem System.[15] Eben weil das Internet kein Zentrum hat, weiß niemand, wie es im Schadensfall konkret reagieren wird. Aus dem gleichen Grund kann auch keine Karte des Internets erstellt werden. Zwar können Kapazitäten zur Sicherung bereitgehalten und Reserven aufgebaut werden. Es ist aber nicht möglich, vorherzusagen, welche konkreten Auswirkungen ein Ausfall hat. Diese können nur nachträglich rekonstruiert werden. Die Komplexität und Vielschichtigkeit der technischen Komponenten sowie der Grad an Vernetzung und Interdependenz verhindern Vorhersagen und Simulationen.
Redundanz, die Architektur des Internets und die Industrien der Konnektivität
In einem Interview erklärt Mareike Jacobshagen, Marketing-Managerin von Interxion, den Zwischenfall mit einem „Versagen der redundanten Systeme“.[16] Auf der lokalen Ebene des Rechenzentrums geschieht genau das, was nicht geschehen darf: Die Redundanzschleifen, die daraus ausgerichtet sind, im Fall eines Ausfalls Schritt für Schritt einzuspringen, fallen selbst aus. Für IT-Dienstleister ist Redundanz auf verschiedenen Ebenen essentiell: es werden nicht nur redundante Energieversorgungssysteme etabliert, auch die Zertifizierung von Datensicherheit gegenüber böswilligen Angriffen sowie technischem Versagen gilt, wie sich beim Blick auf die einschlägigen Homepages zeigt, als zentrales Verkaufsargument. Daten werden redundant auf verschiedenen Datenträgern (mitunter von unterschiedlichen Herstellern) und an verschiedenen Standorten gespiegelt und umfangreiche Maßnahmen zum Schutz vor Angriffen in die Wege geleitet. Entsprechende Standards und Zertifikate ermöglichen, so das Versprechen, Vergleichbarkeit und eine nachvollziehbare Datensicherheit.
Redundanz bedeutet die ständige Verfügbarkeit funktional identischer Ressourcen innerhalb eines technischen Systems, die bei einem Störungsfall die Aufgaben der ausgefallenen Komponenten übernehmen können, im Normalfall aber nicht genutzt werden.[17] Für die Energieversorgung von Rechen- und Datenzentren wird gemäß internationaler Standards sogenannte kalte Standby-Redundanz eingesetzt. Parallel zum System der Stromversorgung aus dem regionalen Netz verfügt jedes größere Rechenzentrum über Dieselgeneratoren, die im Notfall einspringen. Es sind stets mehrere Generatoren, üblicherweise drei, vorhanden, um sich auch gegen den Ausfall eines Generators abzusichern. Auf die Qualität des Diesels wird meist hoher Wert gelegt und der Kraftstoff regelmäßig ausgetauscht. Aufgrund des enormen Energieverbrauchs eines Rechenzentrums kann nur für einige Stunden Notbetrieb Kraftstoff vorrätig gehalten werden. Die Kosten für die Redundanz machen entsprechend einen wichtigen Punkt der Preiskalkulation aus.
Es reicht dabei nicht, schlicht eine Stromquelle als Ersatz bereitzuhalten, weil bereits Unterbrechungen von wenigen Millisekunden die Elektronik zerstören können. Deshalb sind aufwändige Systeme der unterbrechungsfreien Stromversorgung (uninterruptible power supply) nötig, um mögliche Schwankungen im Stromnetz auszugleichen. Die entsprechenden Systeme, die selbst enorme Mengen an Energie benötigen, koppeln das Rechenzentrum bei Bedarf vom allgemeinen Stromnetz ab, was beispielsweise bei Spannungsschwankungen oder Frequenzänderungen wichtig ist. Darüber hinaus beinhaltet unterbrechungsfreie Stromversorgung gemäß der EU-Norm EN 62040 die genannten Notstromkomponenten, die zumindest kurzzeitig eine autarke Stromversorgung sicherstellen. Im Falle eines Stromausfalls greift zunächst ein Batteriespeicher ein, der das Netz so lange am Laufen hält, bis die sogenannte Netzersatzanlage, d.h. der Notstrom, aktiviert ist, was im Fall von hochfahrenden Dieselgeneratoren einige Minuten dauern kann und genau synchronisiert werden muss.
Redundanz betrifft aber nicht nur Datensicherung und Energieversorgung auf lokaler Ebene, sondern ist von Beginn an Bestandteil der Architektur des Internets, wie sie 1964 von Paul Baran unter dem Titel On Distributed Communications Networks für die RAND-Corporation formuliert wird.[18] Baran beschäftigt sich damit, wie ein Kommunikationsnetzwerk einen Angriff – einen Atomangriff – überleben kann und welche Formen der Konnektivität, d.h. welche Architektur von Knoten und Verbindungen für die Gestaltung des Netzwerks angesichts dieser bedrohendsten aller Bedrohungen sinnvoll sind, um handlungsfähig zu bleiben. Handlungsfähig bedeutet, das Kommando zum Gegenschlag geben und d.h. über technische Infrastrukturen kommunizieren zu können.
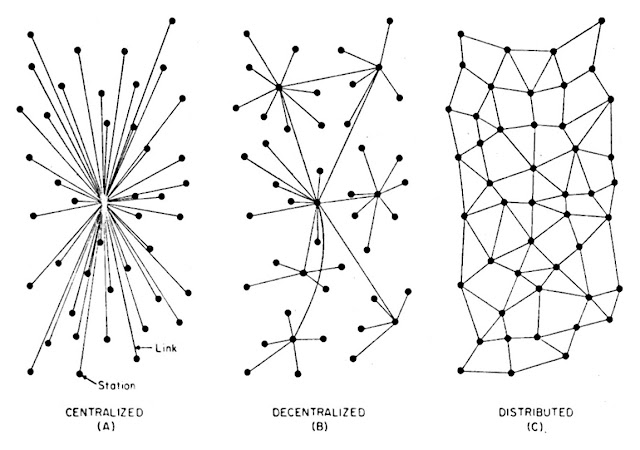
Baran, Paul: »On distributed communications networks«. In: IEEE Transactions CS-12/1 (1964), S. 1-9, hier: S. 1.
Baran unterscheidet drei Netzwerktypen, die auf einer zur Ikone des Internetzeitalters aufgestiegenen Abbildung zu sehen sind: zentralisierte, dezentralisierte und distribuierte Netze. Als Alternative zu zentralisierten und dezentralisierten Netzen, die aufgrund ihrer Konzentration auf herausgehobene Knoten, an denen alle Kanäle zusammenlaufen, besonders gefährdet sind, schlägt Baran eine Topologie distribuierter Netze vor. Als ihr wesentliches Merkmal benennt er die Redundanz ihrer Verbindungen. Ein zentralisiertes Netz wäre durch einen einfachen Schlag auf den zentralen Knoten ausschaltbar, während ein distribuiertes Netz mit möglichst vielen gleichberechtigten Knoten und ebenso vielen oder mehr Verbindungen ohne Hierarchie kaum zu eliminieren sei. Die Lösung der distribuierten Netze besteht in der Ausdehnung und Multiplizierung der potentiellen Ziele eines Angriffs auf die Kommunikationsinfrastruktur. Wird nur ein Knoten ausgeschaltet, gibt es weiterhin genügend Verbindungen zwischen allen anderen Knoten.
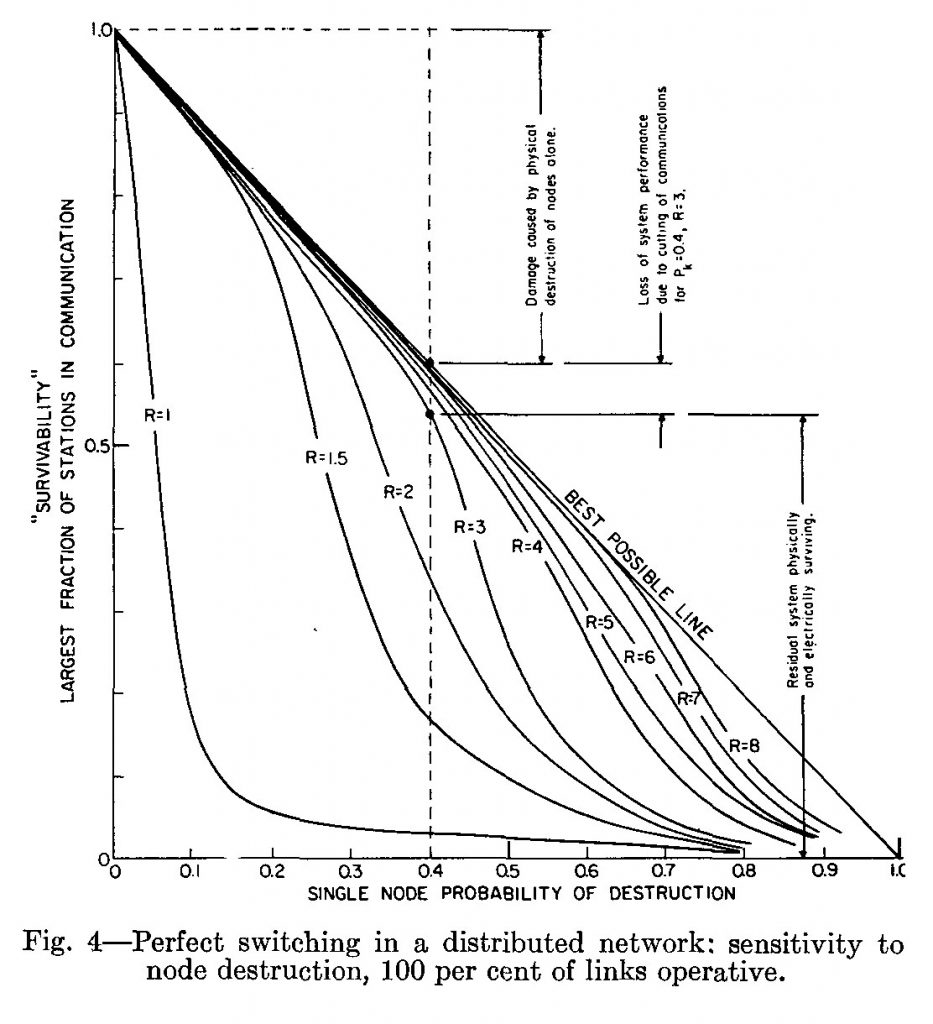
Baran, Paul: »On distributed communications networks«. In: IEEE Transactions CS-12/1 (1964), S. 1-9, hier: S. 2.
Die von Baran vorgeschlagene Architektur der Redundanz hängt eng mit dem von ihm entwickelten Verfahren des packet switching zusammen. Alle übertragenen Daten werden diesem Modell zufolge in kleine, standardisierte Pakete gestaffelt, die jeweils unterschiedliche Pfade von Knoten zu Knoten nehmen. An jedem Knoten werden die Pakete verschiedener Absender in der Reihenfolge ihrer Ankunft verarbeitet und ihre weiterführenden Routen anhand des sogenannten Headers, einem Paketschein analog, abhängig von der Auslastung des Netzes festgelegt. Niemand muss planen oder wissen, welchen Weg ein Paket nehmen wird. Weil an den Knoten Traffic ungeachtet seiner Herkunft, der verwendeten Hardware und seiner Inhalte, aber ausschließlich in der formalisierten Weise, die das Protokoll vorgibt, weitergeleitet wird, können User bzw. die Anbieter von Diensten sicher sein, dass Daten so am Ziel ankommen, wie sie verschickt werden, selbst wenn Pakete auf dem Weg verschwinden oder Knoten ausfallen.
Das Ziel einer sicheren Übertragung kann aus Barans Sicht anders als das einer schnellen Kommunikation nur dann erreicht und das Netzwerk stabilisiert werden, wenn die Anzahl der Knoten optimal auf die Anzahl der Verbindungen abgestimmt wird. Dazu wird erstens ein digitales Codierungsverfahren verwendet, das durch Redundanz gegen Angriffe geschützt ist und automatisiert werden kann, sowie zweitens eine Kommunikationsinfrastruktur entworfen, die über mehr Verbindungen verfügt als für den normalen Betrieb notwendig sind. Es geht in einem solchen Netz nicht darum, jeden Knoten von jedem anderen Knoten aus in einer Direktverbindung erreichen zu können, sondern um die Stabilität jeder temporären Verbindung. Vernetzung bedeutet Mitte des 20. Jahrhunderts, nicht mehr jeden Empfangsort direkt mit jedem anderen verbinden zu müssen. Nach Barans Berechnung reicht eine Konnektivität von lediglich drei von jedem Knoten abgehenden Verbindungen für ein stabiles Netz, das redundant genug ist, um beim Verlust von einzelnen Knoten ohne Einschränkung zu funktionieren. Seit dem maßgeblichen Paper „A Protocol for Packet Network Intercommunication“ von Vinton Cerf und Robert Kahn, das 1973 die Grundlagen des Übertragungsprotokolls TCP formuliert, wird Konnektivität wird nicht als direkte Verbindung zwischen Knoten gedacht, sondern als Potential des Netzwerks, in dem jede Verbindung redundant ist.[19] Redundanz ist damit ein systemischer Bestandteil der Netzwerkarchitektur.
Nach dem Modell des Textes von Cerf und Kahn operieren Knoten als Black Boxes, einfach und fehlerresistent, aber unbeteiligt an dem, was durch sie hindurchgeht, auf der Grundlage variabler Hardware und vollständig automatisiert. Da die Aufnahme- und Verarbeitungskapazitäten jedes Knotens technisch begrenzt sind, droht bei zu hoher Auslastung trotz aufwändiger Synchronisationsverfahren die Verlangsamung der Übertragung oder der Verlust von Paketen. An den Knoten werden die Pakete, dem ursprünglichen Protokoll zufolge, in automatisierten Verfahren schnellstmöglich in der Reihenfolge ihres Ankommens verarbeitet (Best-Effort-Principle). Wenn mehr Pakete ankommen als Zwischenspeicher oder Bearbeitungszeit zur Verfügung steht, werden sie nicht angenommen, gehen verloren oder werden gelöscht. „If all available buffers are used up, succeeding arrivals can be discarded since unacknowledged packets will be retransmitted.”[20] Dies stellt insofern kein Problem dar, weil der Verlust von Paketen in diesem Modell bereits einkalkuliert ist: „No transmission can be 100 percent reliable.“[21] Die Redundanz der Übertragung gilt seit Baran als höchstes Ziel jedes Netzwerkmodells und wird auch von Cerf und Kahn fortgeführt: nicht nur bei der Zerstörung von Knoten, sondern auch beim Verlust einzelner Pakete soll das Netzwerk weiterhin operationsfähig sein. Automatisch werden daher Ersatzlieferungen vom vorhergehenden Knoten angefordert, wenn etwas fehlt. Der empfangende Knoten sendet eine Bestätigung für das Paket an den vorherigen Knoten und die digitale Kopie auf dem Ausgangsknoten wird gelöscht. Kommt keine Empfangsbestätigung, wird das Paket erneut auf einer anderen Route versandt.
Die Gefährdungslage liegt heute nicht mehr in feindlichen Atomschlägen, sondern in der Interdependenz komplexer Systeme, in denen sich Störungen unterschiedlichen Ursprungs rasch ausweiten und durch globale Vernetzung zu Kettenreaktionen der Ansteckung führen können. Der Frankfurter Ausfall, eine Woche später in einem Twitter-Statement von Interxion als Serviceunterbrechung bezeichnet, ist also nicht nur ein einfacher technischer Schaden, sondern als Ausfall aller redundanten Systeme, als Versagen der Redundanz selbst, ein Worst-Case-Szenario für eine Industrie, die konstante Konnektivität bei größtmöglicher Redundanz sicherstellen möchte, beeinträchtigt aber – wie beschrieben – die Operationen des Internets nur marginal. Der Betrieb ist nach wenigen Minuten wieder regulär und es gibt keinen Datenverlust, weil allein die Stromversorgung betroffen ist. Deutlich wird jedoch, dass das Internet wie jede Sicherheitstechnologie den Ausfall einkalkuliert und dessen Wahrscheinlichkeit im Sinne dessen, was Paul Virilio den „integralen Unfall“[22] genannt hat, nie ausschalten kann.
Zertifikate der Resilienz
Das Internet ist gemäß der vorgestellten Modelle keineswegs auf fehlerfreien Betrieb ausgerichtet. Es unterliegt vielmehr einem fehlertoleranten Design, das Störungen nicht ausschließen soll, sondern als unvermeidbaren Effekt der technischen Komplexität durch redundante Kapazitäten selbsttätig abfedert. Entsprechend lautet eine Schlussfolgerung aus dem bereits zitierten Aufsatz über die Häufigkeit des Ausfalls von IXPs: „Our analysis shows that redundant peering strategies may increase the resilience to outages.”[23] In diesem Sinne hat die Redundanz, die bei Baran noch zur Lösung der Herausforderungen des Kalten Kriegs gedacht war, mit dem Aufstieg des Internets zum globalen Medium ihre Funktion gewandelt. Es geht nicht um die vollständige Vermeidung jeden Risikos – weder in der heutigen Gestalt skalenfreier Netze, die nicht distribuiert, sondern dezentral sind, noch in der Redundanz von Paketen im packet switching. Stattdessen liegt die Resilienz des Internets in seinen Kapazitäten zur Anpassung an kontinuierliche Instabilität und zur Rückkehr in einen funktionierenden Zustand nach Störungen. Es gibt keinen Normalzustand unterbrechungsfreier Operation, weil diese immer von Störungen begleitet ist. Charakteristisch ist daher ein Modus permanenter Adaption, der das Internet als System der Resilienz ausweist.
Der Begriff der Resilienz, der Anfang der 1970er Jahre vom kanadischen Ökologen Crawford S. Holling in seinem Aufsatz „Resilience and Stability of Ecological Systems“ als generelle Eigenschaft komplexer Systeme beschrieben wird, artikuliert ein neues Verständnis dessen, was stabile Zustände konstituiert.[24] Das Modell der Resilienz erlaubt, die Reaktionen eines Systems auf Stress und Veränderungen als eine operationale Strategie des Risikomanagements zu beschreiben. Resilienz bezeichnet die Menge an Perturbation, die ein System absorbieren kann, bis es einen anderen temporär stabilen Zustand ausbildet.[25] Nach einer Störung findet ein resilientes System nicht einfach in ein stabiles Gleichgewicht zurück, sondern erreicht einen neuen Zustand durch die Setzung neuer Normen und adaptierter Schwellenwerte der Stabilität. Ein solches System kennt keinen einzelnen, optimalen Zustand, sondern nur Multistabilität – es kann sich, in anderen Worten, flexibel an jegliche Störungen und Veränderungen seines Außen anpassen, weil es keinen festen Zustand hat.
Insofern Resilienz als die Fähigkeit eines Systems zur Absorption von Veränderungen bei fluktuierenden Außenbedingungen weit über die Ökologie hinaus zum Ziel des individuellen Verhaltens, der Anpassungsfähigkeit sozialer oder ökonomischer Institutionen sowie zur Grundlage smarter Technologien wird, bildet sie die Grundlage einer neuen Form von Biopolitik. Diese ist auf zukünftige Ereignisse in dynamischen, unvorhersagbaren Umgebungen ausgerichtet, setzt bei Holling als adaptive environmental management die Absorption von Schwankungen methodisch ein und dehnt diese Kapazitäten gegenwärtig angesichts von Risikofaktoren wie Terrorismus oder dem Klimawandel auf planetarischen Maßstab aus. Durch Resilienztraining soll das Unerwartbare erwartbar gemacht werden – durch die Vorbereitung darauf, dass Unerwartetes eintreten wird, kann Holling zufolge der Umgang damit erlernt werden: „The unexpected can be expected.“[26] An die Stelle stabiler Zustände des Gleichgewichts treten das Training eines Systems in permanentem Ausgleich, der Aufbau von Ressourcen für den Notfall und die Herausbildung adaptiver Kapazitäten durch die Ausweitung bzw. Verengung von Grenzwerten, an denen ein System seine temporäre Stabilität aufgibt. Eben diese Maßnahmen, die nicht mehr an der Rückkehr in die stabilen Zustände der Vergangenheit, sondern an der flexiblen Anpassung an zukünftige Schwankungen orientiert sind, werden von den Sicherheitsmaßnahmen von Rechenzentren Schritt für Schritt umgesetzt.[27] Sie sind stets auf das Potential eines zukünftig eintretenden Zwischenfalls gerichtet, der sich nicht vermeiden, sondern nur durch Adaption in das System integrieren lässt.
Sterbenz, James P./Hutchison, David/Çetinkaya, Egemen K./Jabbar, Abdul/Rohrer, Justin P./Schöller, Marcus/Smith, Paul: »Resilience and Survivability in Communication Networks. Strategies, Principles, and Survey of Disciplines«, in: Computer Networks 54 (2010), S. 1245–1265, hier: S. 1253.
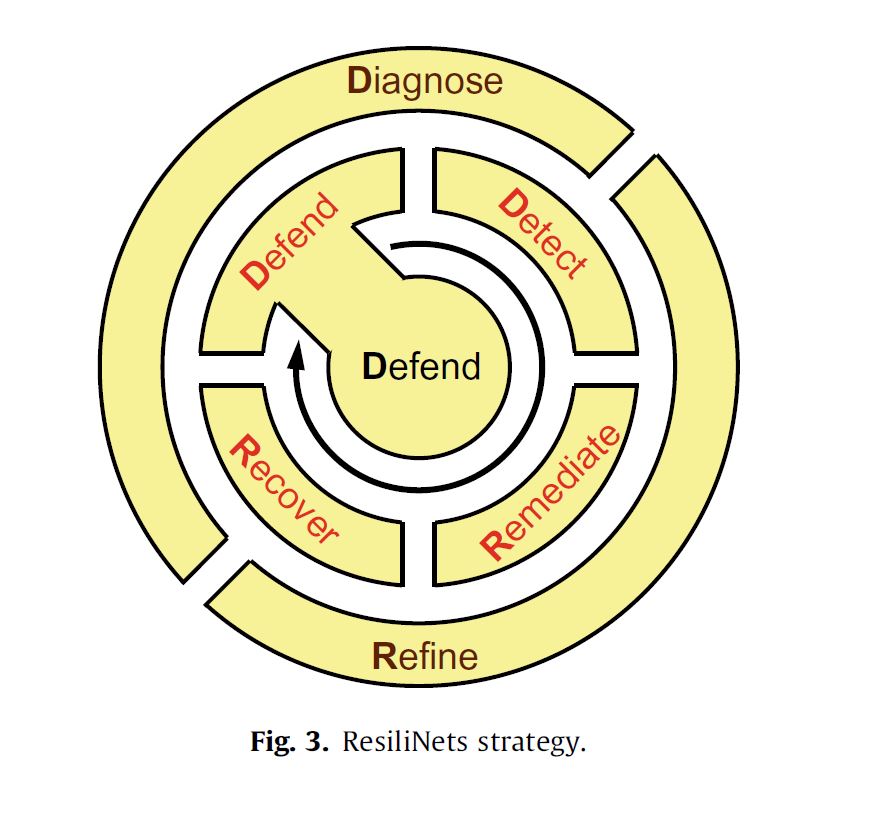
Unter dem Titel Resilinet hat eine Gruppe von Informatikern einen entsprechenden Strategievorschlag für ein „architectural framework for resilience and survivability in communication networks“[28] gemacht, der sich strukturell in den Zertifizierungsratgebern von Regierungsinstitutionen wiederfindet. Diese Strategie ist in einer Grafik zusammengefasst, deren Formel D2R2+DR lautet. Den passiven Kern, also das Ziel dieser Strategie, bildet defend. Die erste aktive Phase der Resilienz besteht im Fall einer wie auch immer geratenen Störung in den vier sofort einzuleitenden Schritten detect, remediate, recover und defend. Die zweite aktive, nunmehr retrospektive und auf die Evolution des Systems ausgelegte Phase besteht aus diagnose und refine.[29] Mit Hilfe dieses Schemas soll ein Knoten resilient gemacht und sein Ausfall verhindert werden.
Dieses Vorgehen folgt Hollings Annahme, dass Vorhersage, Antizipation oder gar Steuerung zukünftiger Zustände eines Systems unmöglich sind, weil künftige Kontingenzen und ihre Komplexität praktisch wie logisch unvorhersagbar sind.[30] Die einzige Möglichkeit besteht darin, ein System auf die unweigerlich kommenden Disruptionen vorzubereiten und seine Fähigkeit zur Resilienz zu stärken. Das Ziel ist der Aufbau von Kapazitäten zur Stressabsorption. Das Risiko zukünftiger Veränderungen oder Katastrophen kann nicht minimiert, sondern nur durch die Optimierung der Adaptionsleistung, durch mehr Flexibilität und Belastbarkeit gemeistert werden. „A management approach based on resilience […] would emphasize the need to keep options open, the need to view events in a regional rather than a local context, and the need to emphasize heterogeneity. Flowing from this would be not the presumption of sufficient knowledge, but the recognition of our ignorance; not the assumption that future events are expected, but that they will be unexpected.” [31]
Diese Zeilen von 1973 deuten die Bedeutung des Modells der Resilienz für gegenwärtige Politiken des Risikomanagements bereits an. Mit der Betonung von Flexibilität, Mobilität und Fluidität sowie dem Imperativ der Adaption stellt der ökologische Begriff der Resilienz Modelle und Metaphern bereit, die auch auf digitale Infrastrukturen sowie Gesellschaften als Ganzes übertragen werden können. Wenn es keine singulären Zustände der Stabilität gibt, sind permanente Anpassung und dauerhafte Flexibilität angesichts globaler Unsicherheit Anleitungen zu effektiver Adaption, sei es auf institutioneller, auf individueller oder auf technischer Ebene. Der Begriff Resilienz ist mithin zur „übergreifenden Chiffre für einen Umgang mit Risiken, Gefährdungslagen und unkalkulierbaren Ereignissen“[32] aufgestiegen. Resilienz kann entsprechend als zeitgenössische Strategie der Regierung des Lebendigen in planetarischem Maßstab und mithin als Instrument der Gouvernementalität im Sinne Foucaults verstanden werden.[33] Das Internet setzt diese Prinzipien in seiner Architektur um.
Unter dem Namen business continuity management laufende Maßnahmen des Krisenmanagements sind gerade für Bestandteile Kritischer Infrastruktur, die per definitionem andauerndem Risiko ausgesetzt ist und deren Störung gravierende Folgen für die Bevölkerung hätte, essentiell geworden.[34] In Bezug auf digitale Netzwerke wird unterschieden in fault tolerance technischen Fehlern gegenüber, disruption tolerance Verbindungsfehlern gegenüber und traffic tolerance gewollten oder ungewollten Überlastungen der Kapazität gegenüber.[35] Die Maßnahmen des Risikomanagements sollen helfen, sogenannte single points of failure zu vermeiden, also Komponenten, deren Ausfall das gesamte System beeinträchtigen würde. Eine Reihe von Standards legen Verfahrensweisen für den Ernstfall fest, die sicherstellen, dass im Notfall rasch angemessene Entscheidungen getroffen werden können. Die international gültige Norm ISO 27001 spezifiziert unter dem Titel Information Technology – Security Techniques – Information Security Management Systems – Requirements die Voraussetzung für die Einrichtung und Operation von Informationssicherheits-Managementsystemen. Neben den Anforderungen und Zielsetzungen von Informationssicherheit sowie der Kostenkalkulation enthält die Norm Angaben zum Prozessrahmen für das Sicherheitsmanagement. In Deutschland stellt das Bundesamt für Sicherheit in der Informationstechnik Zertifikate über ISO 27001 aus, die jedes größere Rechenzentrum, so auch die betroffenen Anbieter in Frankfurt, vorweisen kann.
Konnektivität und Trennung
Resilienz stellt die Kontinuität der Konnektivität auf infrastruktureller Ebene her – das Netzwerk operiert auch bei Störungen und Ausfällen. Redundanz ist der Mechanismus, der auf unterschiedlichen Ebenen Konnektivität in Vernetzung überführt und so ihre Kontinuität durch das Vorhalten von Reserven gewährleistet. Ein an diesen beiden Prinzipien ausgerichtetes Netzwerk ist vor Ausfällen geschützt. Wie der Frankfurter Zwischenfall zeigt, sind Fehler, technische Probleme und Komponentenversagen zwar unvorhersagbar und müssen als Versagen von Redundanz einkalkuliert werden, bleiben aber weitestgehend folgenlos. Der laufende Betrieb wird durch das Versagen des größten Knotens der Welt für kurze Zeit lokal beeinträchtigt, jedoch nicht nachhaltig gestört.
Es scheint, als wäre die Frage, ob man das Internet abschalten kann, damit beantwortet: Nein, man kann es nicht abschalten, außer im Fall einer globalen Katastrophe. Wie bereits angedeutet, impliziert diese zunächst simple Frage einen weiteren Horizont. Wenn das Internet nicht ausfallen kann, dann verändern sich die Rahmenbedingungen dessen, was disconnection oder auch withdrawal genannt wird. Digitale Enthaltsamkeit mag auf der individuellen Ebene von Entnetzungspraktiken möglich sein, doch bleibt sie an das in groben Zügen beschriebene Sicherheitsdispositiv der Resilienz gebunden. Will man – mit welchem Ziel auch immer – über die gesellschaftliche Abhängigkeit von digitalen Infrastrukturen nachdenken, dann ist es ratsam, diese infrastrukturelle Dimension zu adressieren. Andernfalls bleibt die Debatte auf die voluntaristische Ebene individuellen Rückzugs beschränkt und vernachlässigt dessen Möglichkeitsbedingungen.
Entsprechend stellt sich die Frage, ob es über die temporäre Entnetzung hinaus, die immer schon von den Resilienzkapazitäten des redundanten Systems eingehegt wird, Modi der Unterbrechung gibt, die über ‚digitale Enthaltsamkeit‘ hinausgehen. Was kann disconnection heißen, wenn die obersten Prämissen der Systemarchitektur Resilienz und Redundanz lauten? Der Frankfurter Ausfall unterbricht nur für kurze Zeit einige Verbindungen, zeigt aber vor allem, wie wenig im Ernstfall ausfällt. Um alternative Möglichkeiten der Unterbrechung zu eröffnen, wäre es nötig, nicht am schlichten Akt des individuellen Abschaltens anzusetzen, sondern eben diese Verfahren der Resilienz und der Redundanz in den Mittelpunkt zu stellen. Sie stellen den Betrieb des Netzwerks sicher und können damit zwar die individuellen Praktiken seiner (Nicht-)Nutzung nur indirekt beeinflussen, bilden aber das Dispositiv, das Konnektivität gewährleistet. Vor diesem Hintergrund ist der Möglichkeitsraum von disconnection stets an die Infrastrukturen, Industrien und Ökonomien der Konnektivität gebunden, aus denen man ebenso wenig aussteigen wie man das Internet abschalten kann. Eine Politik der disconnection müsste diese Abhängigkeit ernstnehmen und sich selbst als Element kritischer Infrastrukturen begreifen. Macht besteht in digitalen Kulturen nicht nur darin, Verbindungen herzustellen, sondern sie auch trennen zu können.
Anmerkungen
[1] Derzeit gibt es weltweit rund 350 IXPs, vgl. Philipp Richter/Georgios Smaragdakis/Anja Feldmann/Nikolaos Chatzis/Jan Boettger/Walter Willinger: »Peering at Peerings«, in: IMC ’14. Proceedings of the 2014 ACM Internet Measurement Conference November 5-7, 2014, Vancouver, BC, Canada, S. 31–44. Zur ihrer Funktionsweise vgl. Nikolaos Chatzis/Georgios Smaragdakis/Anja Feldmann/Walter Willinger: »There is more to IXPs than meets the eye«, in: ACM Computer Communication Review 43 (2013), S. 19–28.
[2] Das größte Störungspotential liegt im Ausfall von Domain Name System-Servern (DNS), die einer URL mit einer IP-Adresse abgleichen, also dafür verantwortlich sind, dass die URL, die im Browser eingegeben wird, im Netzwerk mit der IP-Adresse des adressierten Servers identifiziert wird. Durch die Regulierung von DNS-Servern können Webseiten wie etwa in China manuell gesperrt werden. Auch die Ausnutzung von Schwachstellen in Protokollen kann enorme Auswirkungen haben. Vgl. https://www.golem.de/news/internet-infrastruktur-fehlerhafte-router-stoppen-bgp-experiment-1902-139186.html, letzter Zugriff am 2. März 2019.
[3] Gegründet von EUNet aus Dortmund, Xlink aus Karlsruhe und MAZ aus Hamburg, ist DE-CIX heute eine hundertprozentige Tochter des Vereins eco – Verband der Internetwirtschaft.
[4] Vgl. zur Liste der Kunden https://www.peeringdb.com/ix/31, letzter Zugriff am 2. März 2019.
[5] Zu einer Klassifizierung unterschiedlicher Fehlertypen in Datencentern vgl. Yang Liu/Jogesh K. Muppala/Malathi Veeraraghavan/Dong Lin/Mounir Hamdi: Data Center Networks. Topologies, Architectures and Fault-Tolerance Characteristics, New York: Springer 2013, S. 51.
[6] Vgl. James P. Sterbenz/David Hutchison/Egemen K. Çetinkaya/Abdul Jabbar/Justin P. Rohrer/Marcus Schöller/Paul Smith: »Resilience and Survivability in Communication Networks. Strategies, Principles, and Survey of Disciplines«, in: Computer Networks 54 (2010), S. 1245–1265. Für eine Kategorisierung von Risiken für die Infrastruktur des Internets vgl. European Union Agency for Network and Information Security: Threat Landscape and Good Practice Guide for Internet Infrastructure 2015.
[7] Jaron Lanier: Ten Arguments for Deleting your Social Media Accounts right now, New York: Holt 2018, S. 7 sowie Byung-Chul Han: Im Schwarm. Ansichten des Digitalen, Berlin: Matthes & Seitz 2013 Vgl. auch Tero Karppi: Disconnect. Facebook’s affective bonds, Minneapolis: University of Minnesota Press 2018 sowie Siva Vaidhyanathan: Anti-Social Media. How Facebook Disconnects Us and Undermines Democracy, Oxford: Oxford University Press 2018.
[8] Vgl. Pepita Hesselberth: »Discourses on disconnectivity and the right to disconnect«, in: New Media & Society 1 (2017), S. 1–17.
[9] Urs Stäheli hat in ähnlicher Perspektive die Praktiken der Entnetzung dargestellt, in denen „durch permanentes Vernetzen Vernetzung selbst zu einem Problem wird“ (Urs Stäheli: »Entnetzt euch! Praktiken und Ästhetiken der Anschlusslosigkeit1«, in: Mittelweg 36 (2013), S. 3–28, hier S. 10). Er betont, dass Entnetzung sich nicht allein auf ontologischer Ebene beschreiben lässt. In diesem Sinn kann seine soziologische Perspektive auf Bereiche der Entnetzung innerhalb von Netzwerken komplementär zur hier vorgeschlagenen Perspektive auf disconnection außerhalb des Netzwerks verstanden werden.
[10] Vgl. Andreas Folkers: Das Sicherheitsdispositiv der Resilienz. Katastrophische Risiken und die Biopolitik vitaler Systeme, Frankfurt/Main: Campus 2018.
[11] Vgl. http://www.faz.net/aktuell/wirtschaft/diginomics/fehlerkette-bei-interxion-grund-fuer-de-cix-panne-15545001.html, letzter Zugriff am 2. März 2019.
[12] http://www.faz.net/aktuell/rhein-main/frankfurter-rechenzentrum-schockiert-und-betroffen-von-stromausfall-15537500.html, letzter Zugriff am 2. März 2019.
[13] https://twitter.com/DECIX/status/983496548888825856, letzter Zugriff am 2. März 2019. Die Angaben über die Ausfallzeiten unterscheiden sich, weil einige Dienste schon früher betroffen waren. Die hier genannten Zeiten betreffen die Nicht-Erreichbarkeit des DE-CIX, vgl. https://labs.ripe.net/Members/emileaben/does-the-internet-route-around-damage-in-2018, letzter Zugriff am 2. März 2019.
[14] Vgl. Giotsas, Vasileios/Dietzel, Christoph/Smaragdakis, Georgios et al.: »Detecting Peering Infrastructure Outages in the Wild«, in: Proceedings of SIGCOMM ’17, 21.-25. August 2017, Los Angeles.
[15] Vgl. zur Unmöglichkeit der Kontrolle auch Committee on the Internet Under Crisis Conditions: Internet under Crisis Conditions. Learning from September 11, Washington, D.C: National Academies Press 2003, S. 4.
[16] https://www.golem.de/news/interxion-de-cix-rechenzentrumsbetreiber-bekennt-doppelten-ausfall-1804-133792.html, letzter Zugriff am 2. März 2019.
[17] Eine frühe mathematische Theorie der Redundanz technische Systeme haben E.F. Moore und Claude Shannon am Beispiel von Relaisschaltkreisen bereits 1956 vorgestellt: E.F Moore/Claude Shannon: »Reliable Circuits using Less Reliable Relays«, in: Journal of the Franklin Institute 262 (1956), S. 191–208.
[18] Vgl. Paul Baran: »On distributed communications networks«, in: IEEE Transactions CS-12 (1964), S. 1–9 Der Einfluss von Barans Ansatz auf die Entwicklung des ARPANET ist umstritten.
[19] Vinton Cerf/Robert Kahn: »A Protocol for Packet Network Intercommunication«, in: IEEE Transations on Communications 22 (1974), S. 637–648.
[20] ebd., S. 645.
[21] ebd., S. 644.
[22] Vgl. Paul Virilio: »Der integrale Unfall«, in: Christian Kassung (Hg.), Die Unordnung der Dinge. Eine Wissens- und Mediengeschichte des Unfalls, Bielefeld: Transcript 2007, S. 7–8.
[23] V. Giotsas/C. Dietzel/G. Smaragdakis et al., Detecting Peering Infrastructure, S. 13.
[24] Crawford S. Holling: »Resilience and Stability of Ecological Systems«, in: Annual Review of Ecology and Systematics 4 (1973), S. 1–23. Zur Geschichte des Begriffs außerhalb der Ökologie vgl. Sabine Höhler: »Resilienz: Mensch – Umwelt – System. Eine Geschichte der Stressbewältigung von der Erholung zur Selbstoptimierung«, in: Zeithistorische Forschungen 11 (2014), S. 425–443 sowie D. E. Alexander: »Resilience and Disaster Risk Reduction. An Etymological Journey«, in: Natural Hazards and Earth System Sciences 13 (2013), S. 2707–2716.
[25] Fridolin Brand/Kurt Jax: »Focusing the Meaning(s) of Resilience. Resilience as a Descriptive Concept and a Boundary Object«, in: Ecology and Society 23 (2007), S. 1–16, hier S. 2.
[26] Crawford S. Holling: Adaptive Environmental Assessment and Management, New York: Wiley 1978, S. 30.
[27] Vgl. dazu den von der European Network and Information Security Agency angefertigten Bericht Good Practices in Resilient Internet Interconnection, letzter Zugriff am 2. März 2019.
[28] J. P. Sterbenz et.al.: »Resilience and Survivability«, S. 1245.
[29] James P. G. Sterbenz/Egemen K. Çetinkaya/Mahmood A. Hameed/Abdul Jabbar/Shi Qian/Justin P. Rohrer: »Evaluation of Network Resilience Survivability, and Disruption Tolerance. Analysis, Topology Generation, Simulation, and Experimentation«, in: Telecommunication Systems 33 (2011), S. 41, hier S. 1253.
[30] Vgl. Jeremy Walker/Melinda Cooper: »Genealogies of Resilience«, in: Security Dialogue 42 (2011), S. 143–160.
[31] C. S. Holling, S. 21.
[32] Ulrich Bröckling: Gute Hirten führen sanft. Über Menschenregierungskünste, Berlin: Suhrkamp 2017, S. 114.
[33] Vgl. zum Unterschied einer Biopolitik der Bevölkerung in Foucaults Sinn und einer Biopolitik der Resilienz A. Folkers, Das Sicherheitdispositiv der Resilienz sowie Chris Zebrowski: »The Nature of Resilience«, in: Resilience 1 (2013), S. 159–173.
[34] Vgl. A. Folkers, Das Sicherheitsdispositiv der Resilienz, S. 353ff.
[35] Vgl. J. P. Sterbenz/D. Hutchison/E. K. Çetinkaya/A. Jabbar/J. P. Rohrer/M. Schöller/P. Smith, S. 1247.
Literatur
Alexander, D. E.: »Resilience and Disaster Risk Reduction. An Etymological Journey«, in: Natural Hazards and Earth System Sciences 13 (2013), S. 2707–2716.
Baran, Paul: »On distributed communications networks«, in: IEEE Transactions CS-12 (1964), S. 1–9.
Brand, Fridolin/Jax, Kurt: »Focusing the Meaning(s) of Resilience. Resilience as a Descriptive Concept and a Boundary Object«, in: Ecology and Society 23 (2007), S. 1–16.
Bröckling, Ulrich: Gute Hirten führen sanft. Über Menschenregierungskünste, Berlin: Suhrkamp 2017.
Cerf, Vinton/Kahn, Robert: »A Protocol for Packet Network Intercommunication«, in: IEEE Transations on Communications 22 (1974), S. 637–648.
Chatzis, Nikolaos/Smaragdakis, Georgios/Feldmann, Anja/Willinger, Walter: »There is more to IXPs than meets the eye«, in: ACM Computer Communication Review 43 (2013), S. 19–28.
Committee on the Internet Under Crisis Conditions: Internet under Crisis Conditions. Learning from September 11, Washington, D.C: National Academies Press 2003.
European Union Agency for Network and Information Security: Threat Landscape and Good Practice Guide for Internet Infrastructure 2015.
Folkers, Andreas: Das Sicherheitsdispositiv der Resilienz. Katastrophische Risiken und die Biopolitik vitaler Systeme, Frankfurt/Main: Campus 2018.
Giotsas, Vasileios/Dietzel, Christoph/Smaragdakis, Georgios et al.: »Detecting Peering Infrastructure Outages in the Wild«, in: Proceedings of SIGCOMM ’17, 21.-25. August 2017, Los Angeles.
Han, Byung-Chul: Im Schwarm. Ansichten des Digitalen, Berlin: Matthes & Seitz 2013.
Hesselberth, Pepita: »Discourses on disconnectivity and the right to disconnect«, in: New Media & Society 1 (2017), S. 1–17.
Höhler, Sabine: »Resilienz: Mensch – Umwelt – System. Eine Geschichte der Stressbewältigung von der Erholung zur Selbstoptimierung«, in: Zeithistorische Forschungen 11 (2014), S. 425–443.
Holling, Crawford S.: »Resilience and Stability of Ecological Systems«, in: Annual Review of Ecology and Systematics 4 (1973), S. 1–23.
—: Adaptive Environmental Assessment and Management, New York: Wiley 1978.
Karppi, Tero: Disconnect. Facebook’s affective bonds, Minneapolis: University of Minnesota Press 2018.
Lanier, Jaron: Ten Arguments for Deleting your Social Media Accounts right now, New York: Holt 2018.
Liu, Yang/Muppala, Jogesh K./Veeraraghavan, Malathi/Lin, Dong/Hamdi, Mounir: Data Center Networks. Topologies, Architectures and Fault-Tolerance Characteristics, New York: Springer 2013.
Moore, E.F/Shannon, Claude: »Reliable Circuits using Less Reliable Relays«, in: Journal of the Franklin Institute 262 (1956), S. 191–208.
Richter, Philipp/Smaragdakis, Georgios/Feldmann, Anja/Chatzis, Nikolaos/Boettger, Jan/Willinger, Walter: »Peering at Peerings«, in: IMC ’14. Proceedings of the 2014 ACM Internet Measurement Conference November 5-7, 2014, Vancouver, BC, Canada, S. 31–44.
Stäheli, Urs: »Entnetzt euch! Praktiken und Ästhetiken der Anschlusslosigkeit1«, in: Mittelweg 36 (2013), S. 3–28.
Sterbenz, James P. G./Çetinkaya, Egemen K./Hameed, Mahmood A./Jabbar, Abdul/Qian, Shi/Rohrer, Justin P.: »Evaluation of Network Resilience Survivability, and Disruption Tolerance. Analysis, Topology Generation, Simulation, and Experimentation«, in: Telecommunication Systems 33 (2011), S. 41.
Sterbenz, James P./Hutchison, David/Çetinkaya, Egemen K./Jabbar, Abdul/Rohrer, Justin P./Schöller, Marcus/Smith, Paul: »Resilience and Survivability in Communication Networks. Strategies, Principles, and Survey of Disciplines«, in: Computer Networks 54 (2010), S. 1245–1265.
Vaidhyanathan, Siva: Anti-Social Media. How Facebook Disconnects Us and Undermines Democracy, Oxford: Oxford University Press 2018.
Virilio, Paul: »Der integrale Unfall«, in: Christian Kassung (Hg.), Die Unordnung der Dinge. Eine Wissens- und Mediengeschichte des Unfalls, Bielefeld: Transcript 2007, S. 7–8.
Walker, Jeremy/Cooper, Melinda: »Genealogies of Resilience«, in: Security Dialogue 42 (2011), S. 143–160.
Zebrowski, Chris: »The Nature of Resilience«, in: Resilience 1 (2013), S. 159–173.
Florian Sprenger ist Juniorprofessor für Medienkulturwissenschaft an der Goethe-Universität Frankfurt. Forschungsschwerpunkte: Geschichte der Medientheorie, künstliche Environments im 20. Jahrhundert, Infrastrukturen der Überwachung in der Gegenwart. Letzte Publikationen: Politik der Mikroentscheidungen. Edward Snowden, Netzneutralität und die Architekturen des Internets, Lüneburg (Meson Press) 2015; Hg. mit Christoph Engemann: Internet der Dinge – Über smarte Objekte, intelligente Umgebungen und die technische Durchdringung der Welt, Bielefeld (transcript) 2015.